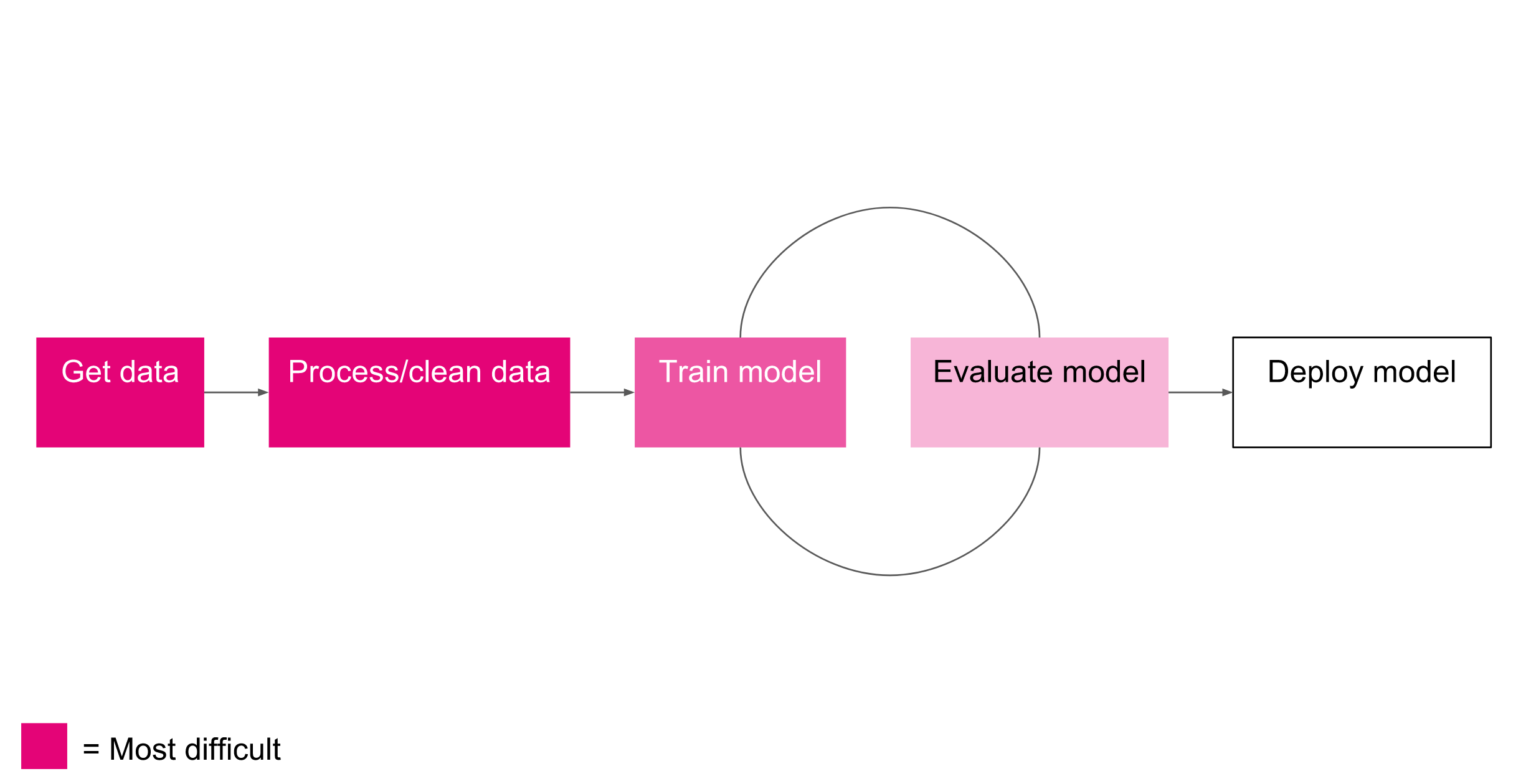
The first step in any machine learning pipeline is data acquisition. There are generally four methods of obtaining data:
The first three are fairly similar. The last provides the power to design custom features with the trade-off of money and time. That said, creating your own dataset is definitely something that should be encouraged in the right circumstance. Sometimes it is tempting to limit the scope of the problems that can be solved by the types of data that you have readily available. If you are using ML to solve a problem for which no perfect dataset exists, instead think of ways that you may be able to leverage combinations of existing data, or maybe better yet, create a system by which you can create new data that you can then use to train a model.
The data preparation, preprocessing and normalization
steps are often the most time consuming and code-heavy part of the pipeline (see Preprocessing & Normalization). It's also the most important step to get right. Most machine learning algorithms only operate well on data that is within a certain range (e.g. small values between -1.0 and 1.0 or 0.0 and 1.0) with a standard variance. Real-world data might have arbitrary values with units in the millions, or tons of outliers that need to be removed. Once you've cleaned and pre-processed your data, you will need split it into groups to be used for training and testing. Correctly preparing and partitioning your data before using it for training is often the key to developing a successful model.
Now comes the fun part, its time to train your model (using your training data only). Training can take anywhere from a few minutes to hours or days depending on your model architecture or compute hardware. As a rule of thumb, training your model on a GPU will yield training times orders of magnitude faster than CPU training and should almost always be preferenced.
During the training process, your data is iteratively fed into the model in small batches, subsets of the entire training dataset, called mini-batches. Once your model has seen all of the training data, it has completed one epoch. Training usually requires multiple epochs and ends when validation loss (error) stops decreasing. More on that soon...
Once you've trained your model, its time to evaluate its performance (see Performance Measures). You usually do this by freezing the model parameters, running the model on the test data, but this time without updating the parameters like you do during training. During evaluation the goal is to measure the trained model's error/accuracy on unseen data. Once you've got a measure of how effective your model is, its time to train another model to try and beat it. The ML pipeline often requires many iterations of training and evaluating; the goal being to reduce the error on your test data.
It is not uncommon to do this 10 to 100+ times, choosing to use the model that performs the best on the testing data in production. For this reason, it is important to keep track of different experiments in an organized way.
An advanced technique to quickly and effectively automate the training and evaluation cycle is to use hyperparameter search.
Once you've got a trained model that performs adequately it's time to deploy it live. This process of using your trained model, called model inference instead of learning , looks different for every application, but can include things like integrating it into a server-side process that handles web API requests, bundling it in a mobile application, or using Tensorflow.js to deploy it to the web. Most models are trained to learn model weights that are then frozen during production. However, some models incorporate live unseen data into the training process. These models are said to operate, "online", and their is little distinction between training and deployment; the model is always learning.
Next: Types of Learning
Previous: Machine Learning Models
Return to the main page.
All source code in this document is licensed under the GPL v3 or any later version. All non-source code text is licensed under a CC-BY-SA 4.0 international license. You are free to copy, remix, build upon, and distribute this work in any format for any purpose under those terms. A copy of this website is available on GitHub.