In Part 1 and Part 2 of this tutorial we covered data preparation and model training. In this chapter, we'll learn how to use our trained model to generate text. We'll also learn how to convert our Keras model into a Tensorflow.js model so that we can deploy it in a browser environment.
The process of using our trained model is called inference. In many neural network tasks inference is a simple process: You feed the trained model unseen data and use the model's output, as is, as your prediction. If the task is a regression problem, the model outputs scalar or vector values that represent the predictions. If the task is a classification problem, the softmax function at the end of the model ensures that the output represents a probability distribution where the value of each element in the vector corresponds with the model's confidence the input sample belongs to that class.
Our inference process is a bit more complicated than that. As we've seen, character-level text generation is a classification problem, and our training process reflects that. But now that it's time to actually use our model we employ a few extra steps beyond the usual "pick the highest output class label" inference scenario.
We'll use a technique called autoregression to feed the model's output at one prediction step as its input during the next prediction step. This behavior can be thought of as the ML equivalent to a snake eating its own tail. The model will begin with a deterministic input, or seed phrase. From there it will sample new characters from its own predictions, each time adding them to the buffer of characters used as input. Quickly, the model will enter a hallucination loop, where new text is generated based not on the seed phrase but instead entirely on input that was generated using the model's past predictions.
Before we see how this works in code, make sure you have a trained model checkpoint located at the path below.
char-rnn-text-generation/checkpoints/base-model/checkpoint.hdf5
If you skipped ahead, or weren't able to train a model in the last chapter, you can download the pre-trained model here (9.5 MB).
We are going to author a generate.py script that creates new tweets using our trained model. Copy the following code snippet into generate.py, we'll discuss how it works below.
import os
import utils
import numpy as np
from keras.models import load_model, Sequential
# the number of classes from our model's output distribution to truncate
# and re-scale before sampling. More on this below.
TOP_N=2
LENGTH=2048 # the number of characters to generate
SEED="This is a seed sentence."
CHECKPOINT_PATH=os.path.join('checkpoints', 'base-model', 'checkpoint.hdf5')
def main():
# load the trained model from a saved weight checkpoint
model = load_model(CHECKPOINT_PATH)
# build inference model
inference_model = build_inference_model(model)
# assign the inference model the weights from the saved checkpoints
inference_model.set_weights(model.get_weights())
print("loaded model from {}".format(CHECKPOINT_PATH))
text = generate_text(inference_model, SEED, LENGTH, TOP_N)
print("generated text: \n{}\n".format(text))
def generate_text(model, seed, length=512, top_n=10):
"""
generates text of specified length from trained model
with given seed character sequence.
"""
print("generating {} characters from top {} choices."
.format(length, top_n))
print('generating with seed: "{}".'.format(seed))
# a buffer to hold our text as it is generated
generated = seed
# the seed text encoded as integers
encoded = utils.encode_text(seed)
# reset the model states from where they were left during training
model.reset_states()
# feed the seed text into the model to set it's internal RNN states
for idx in encoded[:-1]:
# we wrap each character in a double array so the shape is (1, 1)
x = np.array([[idx]])
# we don't care about the predicted output here.
model.predict(x)
# the index of the next character in the sequence, this will change
# each time we predict a new character
next_char_index = encoded[-1]
for _ in range(length):
x = np.array([[next_char_index]])
# input shape: (1, 1)
probs = model.predict(x)
# output shape: (1, 1, vocab_size)
next_char_index = utils.sample_from_probs(probs.squeeze(), top_n)
# append the output to the generated sequence buffer
generated += utils.ID2CHAR[next_char_index]
# return the sequence buffer containing our generated text
return generated
# our model was trained with a large batch size and sequence size, but during
# inference we'll make both the batch size and the sequence size 1.
# we'll also make the model weights untrainable.
def build_inference_model(model, batch_size=1, seq_len=1):
"""
build inference model from model config
input shape modified to (1, 1)
"""
print("building inference model.")
config = model.get_config()
# edit batch_size and seq_len
config[0]["config"]["batch_input_shape"] = (batch_size, seq_len)
inference_model = Sequential.from_config(config)
inference_model.trainable = False
return inference_model
# given a probability distribution, this function will sample an array index
# from a copy of the distribution that has been truncated to include only
# the top_n index values sorted by probability and re-scaled to sum to 1.0.
def sample_from_probs(probs, top_n=10):
"""
truncated weighted random choice.
"""
# need 64 floating point precision
probs = np.array(probs, dtype=np.float64)
# set probabilities after top_n to 0
probs[np.argsort(probs)[:-top_n]] = 0
# re-normalize probabilities
probs /= np.sum(probs)
sampled_index = np.random.choice(len(probs), p=probs)
return sampled_index
main()
We begin by loading our model via the Keras load_model() function. This utility will load our base-model/checkpoint.hdf5 , which we created using save_model() in train_cli.py. Next, we tweak the structure of this model a bit using build_inference_model(). If you remember from Part 2, we trained our model using moderately large batch size and sequence length values (e.g. BATCH_SIZE=64 and SEQ_LEN=32). These values are both efficient and useful to the training algorithm, but during inference we'll feed our model a single character at each time step. This function restructures our trained model's input size to receive values of 1x1 instead of 64x32. It also sets the model's trainable property to False so that the model's weights won't be updated during inference. build_inference_model() creates a new Sequential Keras model, so we overwrite the new model's random weights with the weight values from our trained model using inference_model.set_weights(model.get_weights()).
Finally, we begin the iterative text generation process using generate_text(). First, we encode our SEED text as integers, reset the model's RNN states from whatever they were left at during training, and feed each character from our SEED text into the inference model one at a time using model.predict(x). We don't bother to store the model's predictions here because we are using SEED to set the model's internal RNN states exclusively.
Next we begin the text generation loop, feeding the last character from the SEED sequence into the model first, followed by samples from the model's own output as its input in each subsequent step through the loop. All the while, each output sample is appended to the generated string, which is eventually returned by the function.
The output from our model is transformed into a predicted character using the sample_from_probs() function, which takes as input a probability distribution and the TOP_N value. Here is where things differ slightly from a conventional classification task.
Sampling is the practice of using your model's output. The way you sample depends greatly on your task; what you are going to do with the data. Most classification tasks care only what the model predicts to be the most likely output class. They select this value as the model prediction, discarding the prediction values for the other classes. This is called "greedy argmax" sampling as the argument, or label, with the highest output value is sampled in a greedy fashion, ignorant of the other label's values. This may sound like a fine method for our purposes too... Let's see what happens when we generate text using greedy argmax sampling, by setting TOP_N=1.
python3 generate.py
This is a seed sentence. I want to see the state of the state of the state of the state of the state of the state of the state of the state of the state of the state of the state of the world. #fb
@Miss_Miss_Man I was thinking about the show tonight and I was there to see the show tonight and I was there to see the start of the day and I was there to see the start of the day and I was there to see the start of the day
You can see that our model's output quickly falls into a loop. Greedy argmax samples from the model in a deterministic way, confidently selecting the label with the highest output value, even if the distribution is near-uniform or multimodal (see Probability Distributions). In order to generate more realistic text, we want to sample from the distribution, not just select the most likely output class. When we sample from a distribution the likelyhood that each input class is selected is equal to the probability value the model has assigned to that class.
Returning to the DNA example from Part 1 of this tutorial series, an output distribution representing the output classes CGAT that contained the values [0.13, 0.42, 0.33, 0.12] would give a 13% likelyhood that C would be selected, a 42% chance G would be selected, and 33% and 12% chance A and T would be drawn respectively. This is similar to how sample_from_probs() works, except in our function we first sort the distribution by value descending, truncate the list such that only the TOP_N values become non-zero, and then re-scale the remaining TOP_N values so they sum to one. If we use our DNA example with a value of TOP_N=2, we first sort CGAT [0.13, 0.42, 0.33, 0.12] -> GACT [0.42, 0.33, 0.13, 0.12, truncate [0.42, 0.33, 0.0, 0.0], and then re-scale [0.56, 0.44, 0.0, 0.0] so the distribution sums to one. According to our sampling algorithm, there is a 56% chance that G will be sampled and a 44% chance that A will be sampled.
Here is an example of running generate.py with several different values for TOP_N:
TOP_N=2
This is a seed sentence... http://bit.ly/17cF1S
RT @Sheriesaton: RT @Stephen_London: @Mario_Cash I was so hungry as a money that is a good day. I'm so sure I'm not a free show. I have a good day to see that. I have a great time to see you tomorrow.
@Shanelle_Money happy bday to you!
@MikeMarie hahahaha yes I want to get the start to my baby bro and that wounder shirts is so good and trust me to the comments. I was there thinkin bout the back that is all about that this morning is always a good day though. I'll be at the bar and see it too.
RT @MissKeriBaby: #FF @Miss_Stacks
RT @ShannonEe: @ShawnMarie_ I was thinkin about it when I get home from the shower and I'm still at this show anyways the show is the best thanks for a lot of thing to me. I had a great time at the bar and start this weekend.
@StarrTweet I want a baby too! I'm starting to send me a baby boy at them to go to the storm on the street to see it!
@MikeMackenzie what are you doing today? I want to go to sleep tomorrow at 10 to get there and still have a great day!
TOP_N=3
This is a seed sentence... http://bit.ly/3cD812 (via @therealsheadur): http://twitpic.com/156scr - I'm gonna be at the beach and then went to the barber of a site this week.
@MissMaria_Beanz I know that shit is so switching to myself to the states. They were the same way today.
@Mike_Marie what are you talking about? Too bad I'm glad I'm going home to go to the game!
@Ms_Starr that wass so sweet than u shout out tho lmao
I love how to go on a business to the convention. It's nice. http://myloc.me/3Emmq
@MissKero I want to give me a sexy big shot off on the bus but the weather was the only one who would live and watch the shadow... I have to watch the show or something.
RT @Mark_Martinez: RT @MistahFantasia: #imattractedto the best of twitter that she said "I have a shot of that shit as hell its so good!"
I love them all!!!!!!! RT @StarBredJoe: I hate this song that I can't be attempted to go on my back. There are no classes, but trying to start the mail of the season.
@Ms_MissKeri ha ha ha ha ha ha http://myloc.me/1elms
TOP_N=5
This is a seed sentence.
What are you doing tonight?!
This is the on my way home. The first person's day is the best tweets.
@MrsGoodie lmaoo hahahaha u got a chick a butt?! Lmmfao u say so I'm not sure what I'm doing
The Bengals have to go at the steps, but not to miss it!
@SantaNastylew that's my followers like that that's an option. Haha!
RT @ToriBelovest: #imthetypeto go to the crib to bring that shit in the world, burger sometimes it's starbucks. I like to buy these situation... I would like to hear it with my back.
Took the best travel acciring top that came out of town if you want an intreditane to mill in.
@Solid_Bad I loves ya tweet lol
RT @MrMarketing: #imatreimand I've been a great place to be on mine and says "whats up with the partner with the coming the worst" on and always tell?
@DenverTony he sharin the success too. Lol
RT @MissArlenicus: @Beanzo @MichaelMelanie who watched that shit?
@server taxes are goin' on it!!
TOP_N=10
This is a seed sentence... #inhameshate
@meditagionapplay Texting the way in all beyond the cheese.
Who wants buy companies back up out?? Why do bad shows do today is her sex with the world has bounced a pitbull of customs way about the blackberry
RT @DonnelleReg: Wow....I don't know that they lost the chicken plowers!!!! #radio
RT @Mashable: I've been sleeping in charge of a glass horse in mind... I can't hang with the precious lil surprising summer cds and candy. I hoe on my mind of play. That's gay!
RT @SongzYuuup: @BrettaShania hahahahahahhaha he lettin us b handling a lil man stat...tht was a lame but
Man I shoulda heard angle busy because their laundry steams
@DancerDay it's a good stuff that had scored senior capabilities around and give you the babies for a fraction. Hi calling. http://bit.ly/2emi00
@Justin_Street Ilmy to the spots for ur day?
I am not about in or easy for someone that I've answeded!!!
If you try to start the bus... My portal...
TOP_N=98: This value effectively samples from the entire distribution as-is, because our utils.VOCAB_SIZE is 98.
This is a seed sentence.
As we closed tomorrow...like using all that track all into my brain....tht would kiel for it! lol
http://www.byemds.com/kevinstadley/jdd2o.awl
Luv @treftcomplet award?
This Son Office is a missed ... And just video chair of the Texas http://bit.ly/13ekk6
@jaredragelogens. Looking forward to go to the receiving discredies!!! =)
Wiechoward Creating So There's 1 them through the pictures with the social splin in absence.. http://bit.ly/x0PXP
@maxwell Thanks for the SEXY!
The Best1 screamed "Transparence" being punishing me back and warm in ca-kid in five of the around. Lol :P
#whyrefollowermaters do i go from wcreverse? ur so psych http://pic.gd/2cfe72
I can't believe WTF the life be dead and sdepage as a founcal pressure
@luckyduchy so I'm so sold.. =)
#rudeobake found you a new female, you're ready, but I just in those gonna do a broadcast make it!
@beatzened that ten unl unduda a fuckhard gogo ct-de'.
@marketwatcher You are kinda better, I don't have breakfast until home!
I'll leave it up to you to determine which TOP_N sampling parameter you prefer. If we were curious, we could compare character frequency histograms produced by different TOP_N values with histograms produced by our validate.txt or test.txt data, and chose whichever TOP_N is the closest to the true character frequency distribution. I've never tried that but it just might work!
Just like with train-cli.py you may find python scripts in the wild which can be used to sample data from trained models. The naming conventions and command-line arguments for these files vary more than the train.py scripts I've seen; they are usually named something like sample.py, predict.py, or generate.py. I've add some of these command-line arguments to our generate.py script for convenience.
wget -O generate_cli.py https://raw.githubusercontent.com/brangerbriz/char-rnn-text-generation/master/generate.py
With this script, you can generate arbitrary-length text from the command line.
python3 generate_cli.py \
--checkpoint-path checkpoints/base-model/checkpoint.hdf5 \
--seed "The meaning of life is " \
--top-n 5 \
--length 10000 > 10k-generated-chars.txt
10k-generated-tweets.txt sould now contain ten thousand characters of generated text.
The meaning of life is to be such a fun time tho
@Derichostilla well that is what I sent! I'm so tired and ima hear your fingers from the corner at the middle of the day with my fav shop at work.
@missmered oh man it was a bit much to see. That's all. I hope so throw their social networking actions are a freaking chance when it's such a fruit!
If you can't wait til you get one of the best favored tips for a serent to tell him you have to be in the car... :) haha
I'm at work watchin memory show http://bit.ly/27cz1
@marketingto I'm going to get together!
RT @MoneyBags: #FF @ThisisMyless @TheRealTotaDoe @Stephanie_Lee @MissKarianna @Master_Sucka @StealthStates @TheDailyLeaf @BigGie_Shirt @MickEysSee
@Deepak_Choe3r08 hey girl whatever how u
@selenagomary I love my boy @jillalexardnort.
@StatusBelieve lol what does that mean??
@sarah_solutions yes you can set them out of the studio for the lunch tonight!
Weezy state coming up and soon somewhere!
@MommyBerlin haha what's that?
@MandyStraight I have to stay in the submitten boy at my house at work its so funny and I'm tryinnnnnnnnn. Have fun today.
@DearTomatoe I have nothing to do. I'm not gonna had a baby tomorrow.
Its all good, they have to state off! http://bit.ly/2caz22
Rich Crash Cold As Funny As Sool Than Mini Market http://bit.ly/4nJg9f
RT @Talablez: The best to get on my way to the show.
@StrangeRose yes insane!
...
Ever wonder what the collective ethos of thousands of tweeters thinks the meaning of life is?
# seed the generate.py with "The meaning of life is " 10 times, appending the
# each first line of output to meaning-of-life.txt. Not the most efficient
# approach, but a quick hack!
for i in {1..10}; do
python3 generate_cli.py \
--checkpoint-path checkpoints/base-model/checkpoint.hdf5 \
--seed "The meaning of life is " \
--top-n 5 \
--length 100 \
| head -n 1 >> meaning-of-life.txt
done
# dump the file to the screen
cat meaning-of-life.txt
The meaning of life is a learning artist. http://www.shakestory.com/ #freestar
The meaning of life is a subtle thing!
The meaning of life is awesome.
The meaning of life is not the same on the bears
The meaning of life is always good though :) let's go to sleep.
The meaning of life is so so cute :)
The meaning of life is a spring blunt and what are they?? It is still a life
The meaning of life is the only way we have a service and we have nothing to save.
The meaning of life is not an entire chair...
The meaning of life is to do this, but she is new to the state of the world, which is great to make money online
The meaning of life is converting our model to Tensorflow.js
Well, that last one's not real. But it is what we'll be doing next!
Tensorflow.js (see Tensorflow.js), or "tfjs", has made an effort to support the loading and saving of Keras models. This allows us to train a model with Keras and then load it into a browser for inference and sampling. Before we can do so, however, we need to use the tensorflowjs python package to convert our checkpoint.hdf5 file to the tfjs model format.
If you've completed Part 1 of this tutorial you should already have tensorflowjs installed. If not, install it like so.
pip3 install tensorflowjs
So far we've been working in a directory named twitterbot-tutorial/char-rnn-text-generation. This directory has held our python code, but as we migrate our model to JavaScript, we'll move out of this directory and create a new folder inside twitterbot-tutorial/. We'll then convert our Keras model to JavaScript.
# leave char-rnn-text-generation/ and create tfjs-tweet-generation/
cd ..
mkdir -p tfjs-tweet-generation/checkpoints/base-model
cd tfjs-tweet-generation
# convert the keras model to a tensorflowjs model
tensorflowjs_converter \
--input_format keras \
../char-rnn-text-generation/checkpoints/base-model/checkpoint.hdf5 \
checkpoints/base-model/tfjs
You should now find several files inside checkpoints/base-model/tfjs. The contents and number of files may differ dependent on your model architecture and library versions.
checkpoints/base-model/tfjs/
├── group1-shard1of2
├── group1-shard2of2
└── model.json
We'll be using Electron as our browser environment. At the time of this writing, there appears to be a bug in tfjs' WebGL backend that prevents the efficient use of a stateful RNN in a traditional web browser. Electron provides a WebKit browser environment that can load and run Node.js code, which will help us sidestep this bug using tfjs-node. We'll create a package.json file which will help us download and manage our dependencies. If you have an NVIDIA graphics card with a CUDA environment installed, you should replace "@tensorflow/tfjs-node" with "@tensorflow/tfjs-node-gpu".
{
"name": "tfjs-tweet-generation",
"version": "0.1.0",
"scripts": {
"start": "electron generate.html",
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "Brannon Dorsey ",
"license": "GPL-3.0",
"dependencies": {
"@tensorflow/tfjs-node": "^0.1.19",
"electron": "^2.0.8"
}
}
The Node Package Manager will use this file to download electron and tfjs-node into a folder called node_modules.
# download the project dependencies into node_modules/
npm install
Next, we'll create an HTML file, generate.html, to contain our tfjs code.
<html lang="en">
<head>
<meta charset="utf-8">
<title>TF.js Tweet Generator</title>
</head>
<body>
<h1>Tensorflow.js Tweet Generator</h1>
<pre id="text">Loading model...</pre>
<script src="generate.js"></script>
</body>
</html>
In this file, we define a <pre id="text"></pre> element which we'll use to render status updates and generated text to the page. We include a generate.js script, which we'll author next.
In this script, we load our converted Keras model and use it to generate text, which we render inside the <pre> tag. We'll build this script in stages, starting with the main function.
// Electron allows us to load Node.js modules using the require() syntax.
// tfjs must be at least v0.12.6 to include support for stateful RNNs
const tf = require('@tensorflow/tfjs')
// tfjs-node adds experimental support for native bindings of the
// Tensorflow C library. Using tfjs-node gives us a significant performance
// boost in relation to the default tfjs cpu and webgl backends.
// If you have an NVIDIA GPU with CUDA installed on your machine, you should
// swap the below line with: require('@tensorflow/tfjs-node-gpu')
require('@tensorflow/tfjs-node')
// This is a JavaScript version of our utils.create_dictionary()
// python function. We use it here to define the CHAR2ID and ID2CHAR constants
const [ CHAR2ID, ID2CHAR, VOCABSIZE ] = createDictionary()
// run the main function, logging any errors to the console
main().catch(console.error)
async function main() {
writeText('Loading model...')
const model = await tf.loadModel('checkpoints/base-model/tfjs/model.json')
writeText('Building inference model...')
const inferenceModel = buildInferenceModel(model)
inferenceModel.setWeights(model.getWeights())
inferenceModel.trainable = false
writeText('Generating text...')
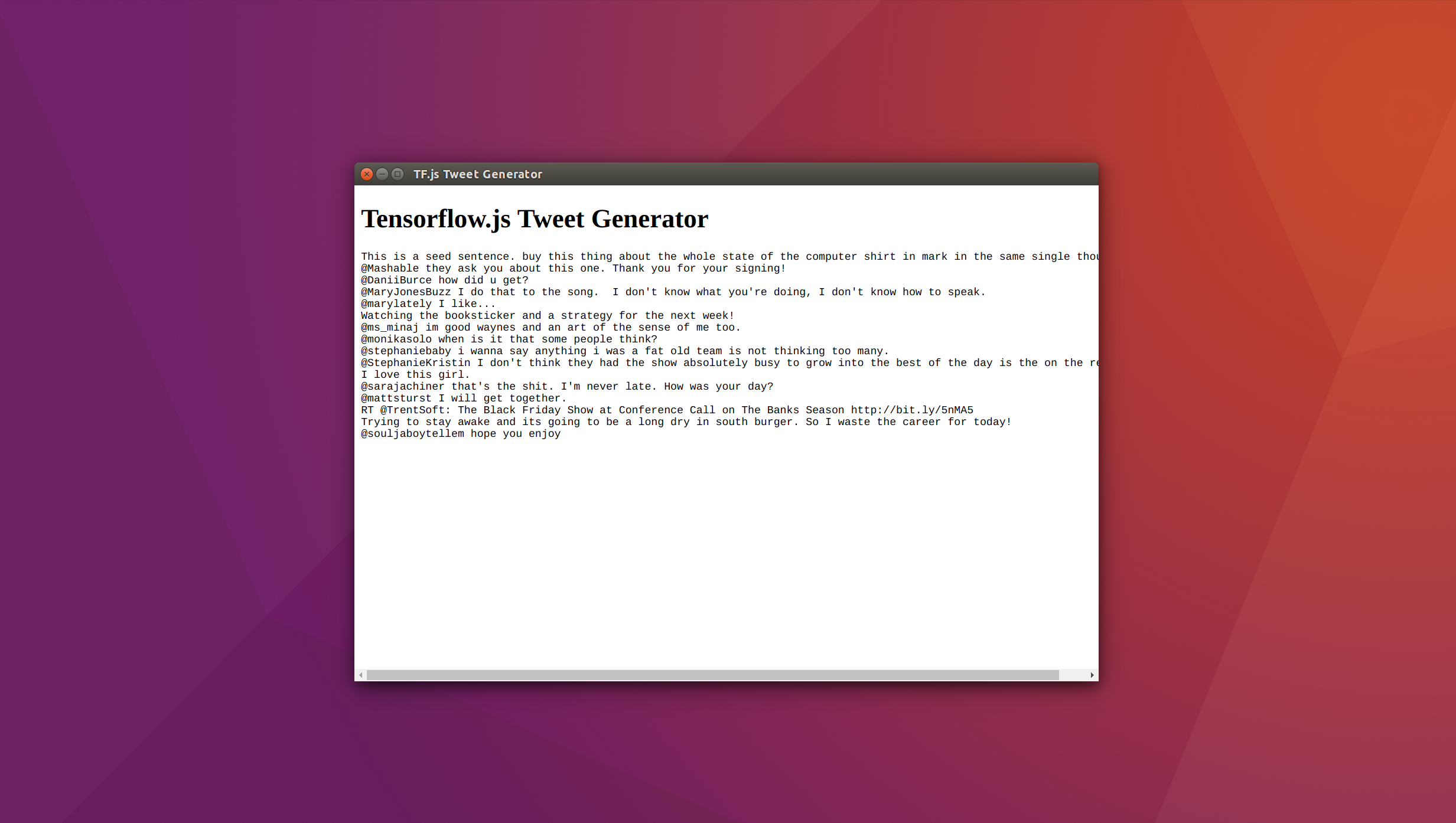
const seed = "This is a seed sentence."
const topN = 5
const length = 1024
const generated = await generateText(inferenceModel, seed, length, topN)
writeText(generated)
}
function writeText(text) {
document.getElementById('text').innerText = text
}
In this file we:
This process should look familiar, as it's basically just a JavaScript version of our generate.py script that interfaces with a webpage instead of a terminal. Tensorflow.js' model converter allows us to easily reuse our Keras model in JavaScript, but it doesn't provide functionality to load and manage our data. For this, we need to author similar utility functions as we did in Python, but this time in JavaScript. Fortunately, Python and JavaScript are very similar languages, so one-to-one translations of this functionality are fairly straighforward. We'll add these functions in JavaScript now.
// the JavaScript equivalent of build_inference_model() in generate.py
// its purpose is to change the batch size and sequence length for inference
function buildInferenceModel(model) {
const batchSize = 1
const seqLen = 1
const config = model.getConfig()
config[0].config.batchInputShape = [ batchSize, seqLen ]
const updatedModel = tf.Sequential.fromConfig(tf.Sequential, config)
return updatedModel
}
// the JavaScript equivalent of generate_text() in generate.py
async function generateText(model, seed, length, topN) {
topN = topN || 10
length = length || 512
console.info(`generating ${length} characters from top ${topN} choices.`)
console.info(`generating with seed: ${seed}`)
let generated = seed
let encoded = encodeText(seed)
model.resetStates()
encoded.slice(0, encoded.length - 1).forEach(idx => {
// tf.tidy() offers memory management for temporary tensor values.
// This functionality is handled automatically in python via garbage
// collection, but must be done manually in tfjs
tf.tidy(() => {
// input shape (1, 1)
const x = tf.tensor([[idx]])
// set internal states
model.predict(x)
})
})
let nextIndex = encoded.length - 1
for (let i = 0; i < length; i++) {
const x = tf.tensor([[nextIndex]])
// input shape (1, 1)
const probsTensor = model.predict(x)
// output shape: (1, 1, VOCABSIZE)
x.dispose()
const probs = await probsTensor.data()
const sample = sampleFromProbs(probs, topN)
generated += ID2CHAR.get(sample)
nextIndex = sample
await tf.nextFrame()
}
return generated
}
// the JavaScript equivalent of encode_text in utils.py
// encodes text characters as integers
function encodeText(text, char2id) {
const dict = char2id || CHAR2ID
return text.split('').map(char => {
const number = dict.get(char)
return typeof number === 'undefined' ? 0 : number
})
}
// draw a discrete sample index from an array of probabilities
// probs will be rescaled to sum to 1.0 if the values do not already
function sample(probs) {
const sum = probs.reduce((a, b) => a + b, 0)
if (sum <= 0) throw Error('probs must sum to a value greater than zero')
const normalized = probs.map(prob => prob / sum)
const sample = Math.random()
let total = 0
for (let i = 0; i < normalized.length; i++) {
total += normalized[i]
if (sample < total) return i
}
}
// truncated weight random choice
function sampleFromProbs(probs, topN) {
topN = topN || 10
// probs is a Float32Array, so we will copy it manually
const copy = []
probs.forEach(prob => copy.push(prob))
// now that it is a regular array we can use the JSON hack to copy it again
const sorted = JSON.parse(JSON.stringify(copy))
sorted.sort((a, b) => b - a)
const truncated = sorted.slice(0, topN)
// zero out all probability values that didn't make the topN
copy.forEach((prob, i) => {
if (!truncated.includes(prob)) copy[i] = 0
})
return sample(copy)
}
// the JavaScript equivalent of create_dictionary() in utils.py
// create dictionaries between char <-> int using the same modified list of
// python printable characters we used during training
function createDictionary() {
const printable = ('\t\n !"#$%&\'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOP'
+ 'QRSTUVWXYZ[\\]^_`abcdefghijklmnopqrstuvwxyz{|}~')
.split('')
// prepend the null character
printable.unshift('')
const char2id = new Map()
const id2char = new Map()
const vocabSize = printable.length
printable.forEach((char, i) => {
char2id.set(char, i)
id2char.set(i, char)
})
return [char2id, id2char, vocabSize]
}
This code should look familiar, so we'll highlight some of the major differences between these Python and JavaScript implementations:
tf.tensor() vs np.array()tf.tidy() and tf.dispose()tf.nextFrame()The Numpy Python library that Keras uses as an interchange format for tensor objects isn't available in JavaScript, so tfjs implements its own tf.tensor() interface in its place. This is an immutible n-dimensional data type that manages data differently depending on the tfjs backend being used. Raw data buffers can be accessed via the Promise returned by tf.tensor().data(), or transfered from memory in a blocking way via tf.tensor().dataSync().
Both the "WebGL" and "tensorflow" tfjs backends store tensors in GPU memory so JavaScript's garbage collector can't release the memory they store. Tensor values in tfjs must be explicitly released when they are no longer needed with tf.tensor().dispose(). Failing to do so will cause a memory leak in your application and can result in memory exhaustion. tf.tidy() provides a convenient memory management wrapper function that automatically disposes any temporary tensors that are created inside its callback. Wrapping synchronous code inside tf.tidy() provides a formed of scoped garbage collection for tensor memory.
tf.nextFrame() returns a promise that resolves when a requestAnimationFrame() has completed. Awaiting this function artificially slows the performance of blocking tfjs code run in a tight loop, throttling tfjs performance in exchange for a slightly less laggy UI experience for the user. Unfortunately, blocking tfjs code runs on the main UI JavaScript thread, so any computationally expensive tfjs operation will freeze the web page until it completes.
We should now be ready to launch our generate.html page using Electron.
# uses package.json to run "electron generate.html"
npm start
Doing so will cause an Electron window to be created. The contents of the window will first show "Loading model...", followed by "generating text...", and after a short while, should be replaced by the output text from our model.
That's it! We should have now have a full version of our pre-trained Keras "base model" running in-browser. In the next chapter, we'll learn how to use Twitter data from individual users to fine-tune our base model via transfer learning, and create Twitter bots intended to mimic specific Twitter accounts.
Return to the main page.
All source code in this document is licensed under the GPL v3 or any later version. All non-source code text is licensed under a CC-BY-SA 4.0 international license. You are free to copy, remix, build upon, and distribute this work in any format for any purpose under those terms. A copy of this website is available on GitHub.